事件裁决是临床试验的核心环节,电话随访作为多中心试验中广泛使用的随访方式,虽能高效获取信息,但传统人工裁决存在工作量大、耗时长、易出错等问题。随着人工智能技术的发展,大语言模型在临床文本处理中展现出潜力,然而其在非结构化对话数据中的应用仍面临准确性不足、时序稳定性差等挑战。
本研究基于中国CT-FFR研究3(China CT-FFR Study 3)的多中心随机临床试验数据,开发了一款领域专用的大语言模型——Fu-LLM。该模型通过对1046例电话随访对话文本进行监督微调,并结合数据增强策略(包括数据重写和数据合成),生成了19162条训练样本,显著提升了模型对临床对话的上下文理解能力。Fu-LLM能够自动裁决五项关键临床事件:信息来源、死亡、住院、手术(如有创性冠状动脉造影)和用药情况,输出“是”、“否”、“不确定”或“未提及”分类结果。
在性能验证中,Fu-LLM表现出色,其与参考标准的一致性达到93.7%,敏感性为97.5%,特异性为95.0%,阴性预测值高达98.2%。与当前主流大语言模型(如GPT-3.5-turbo、GPT-4o、DeepSeek-v3、Claude 3.5-Sonnet、Gemini-2.0-Pro)相比,Fu-LLM在一致性、敏感性和特异性方面均有显著优势。同时,Fu-LLM也超越了经典的机器学习方法(如支持向量机模型),并在与人类随访人员的对比中展现出更高的一致性(92.3% vs. 83.4%)和效率。此外,Fu-LLM在时间漂移测试(Temporal drift testing)中表现出比GPT-4更稳定的性能,避免了因模型版本迭代导致的输出波动。
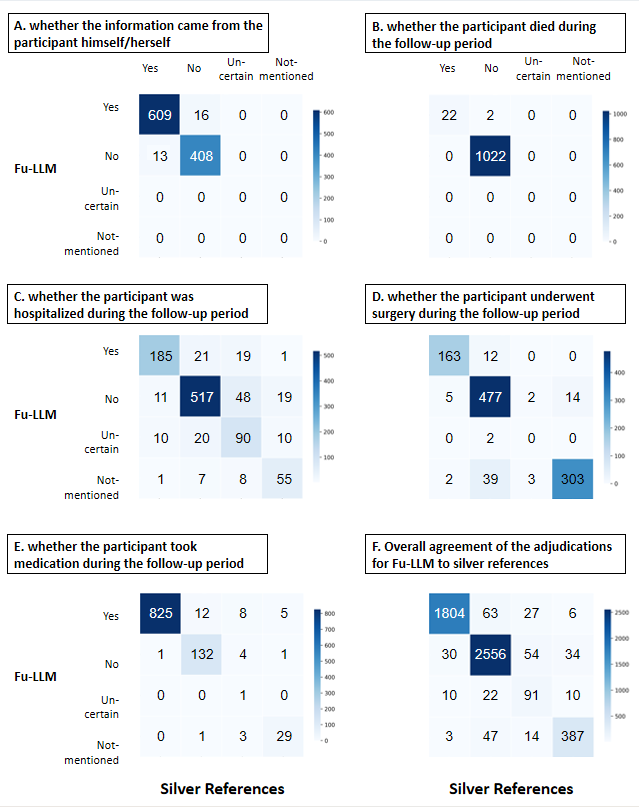
图1. Fu-LLM针对不同事件的裁决性能的混淆矩阵
该研究的成功标志着领域专用大语言模型在临床试验事件自动化裁决中的可行性得到初步验证。Fu-LLM的高阴性预测值意味着可减少约57.2%的人工裁决工作量,有望显著降低大规模临床试验的成本,提升随访数据质量。未来,该模型可进一步整合到电子健康记录系统中,实现实时终点监控,为去中心化临床试验提供技术支持,推动临床研究向数字化、智能化转型。目前,研究团队已公开Fu-LLM的代码和部分数据,供学术社区进一步验证和优化。这一成果不仅为临床终点裁决提供了高效工具,也为大语言模型在医疗领域的专业化应用开辟了新路径。
该研究工作以“A Large Language Model for Clinical Outcome Adjudication from Telephone Follow-up Interviews: A Secondary Analysis of a Multicenter Randomized Clinical Trial”为题于2025年12月1日在学术期刊Nature Communications上发表。黄色网 博士研究生施昭、胡斌,附属金陵医院吴冰倩、钟健为本文共同第一作者,黄色网 附属金陵医院张龙江教授为唯一通讯作者。此项工作也得到来自深睿医疗人工智能实验室、斯坦福大学、香港大学等机构研究者的支持,研究经费部分由国家自然科学基金、科技创新2030——“癌症、心脑血管、呼吸和代谢性疾病防治研究”国家科技重大专项提供。
原文链接://www.nature.com/articles/s41467-025-66910-6